정부 크라우드소싱 플랫폼
공공데이터 (Open Government Data)

글_이주호(네브라스카 주립대학교 행정학과 교수)

4차 산업혁명 시대와 디지털 전환 시대에는 데이터를 21세기의 석유로 비유되기도 한다. 물론 앞으로도 이 데이터의 중요 성이 산업 일반뿐만 아니라 정부에서도 더 커질 것이라고 하는 데는 많은 사람들이 공감할 것이다. 공공데이터는 디지털 플랫폼 정부가 추구하는 개방형 혁신(Open Innovation) 플랫 폼의 한 형태이다. 공공 데이터 플랫폼은 정부가 가지고 있는 원시 데이터(raw data)를 개방하여 누구나 그 데이터를 이용 하여 그들의 목적에 맞게 재활용할 수 있게 하는 것을 목적으로 하고 있다. 이런 면에서 공공데이터는 디지털 공공재라고볼 수 있다. 공공 데이터 플랫폼은 데이터를 가공하여 만든 ‘정 보’가 아니라 가공되기 전 ‘원시 데이터’를 공개한다는 측면에서 내부 데이터 관리에 관한 기존의 투명성 정책과는 차별되는 면에서 혁신적이라고 할 수 있다. 또한 이 원시 데이터에 접근하기 위해서는 기존에는 정보 공개법 같은 제도를 통해 정부기관이 정보 공개 여부를 결정하였다면 공공데이터 플랫폼 에서는 이러한 정부기관의 자의적 정보 공개 결정 과정을 거치지 않고 정부가 선제적으로 원시 데이터를 공개하여 누구나 그 원시 데이터에 접근할 수 있다는 측면에서 혁신적이다.
2022년 10월 31일자 ‘공공데이터 NOW’에 따르면 중앙정부는 55,467개의 파일데이터, 9,649개의 오픈 API, 8,376개의 표준 데이터세트를 공공데이터 플랫폼(data.gov.kr)을 통해 제공되고 있다고 한다. 그러면 정부가 제공하는 공공데이터를 시민들은 얼마나 사용하고 있을까? 누군가는 API를 통해 데이터에 접근하여 사용하고 어떤 사람들은 데이터 파일을 바로 그들의 컴퓨터에 다운로드하고 저장해서 사용할 수도 있다. 한 사람이 혹은 한 조직이 여러 번 공공데이터 플랫폼을 사용할 수도 있다. 이렇듯 다양한 경우의 수가 있어 공공데이터가 얼마나 이용되고 있는지 누가 이용하고 있는지는 정확하게 측정하기는 어려울 것이다. 행정안전부가 공공데이터 플랫폼(data.gov.kr)을 통해 공개한 전국 공공기관의 공공데이터 활용 현황을 보면 2011년부터 2021년까지 11년동안 4십여만 개의 공공데이터를 API를 통해 공개했고 2천 7백만 건이상의 데이터 요청이 있었다고 한다. 우리는 전세계의 많은 중앙 정부 및 지방자치단체가 그들의 재원과 정책을 통해 공
공 데이터 플랫폼과 많은 원시데이터를 제공하기 위해 노력 하고 있는 것을 알고 있다. 우리도 공공데이터 활용 창업 경진 대회, 품질 컨테스트와 같이 공공데이터가 많이 이용되고 확산될 수 있도록 범정부 차원의 노력을 하고 있다.
원시 공공데이터의 공개는 경제적, 사회적 효과뿐만 아니라 정부의 정책결정과 이용자간 지식공유라는 긍정적 효과를 기대하고 있다. 예를 들어 최근 발표된 연구에서는 서울시의 공공데이터 플랫폼이 가져오는 직접적인 연간 경제적 가치를 최소 $2.07 million으로 간접적인 경제적 가치는 약 $50 million로 예측하고 있다(Jeon et al., 2022). 또한 원시 공공 데이터 공개는 시민들이 정부의 의사결정과정과 그 결과에 접근을 할 수 있어서 정부의 투명성을 증진하여 시민에 대한 책임성을 향상시킬 수 있다.
우리가 원시 공공데이터 공개를 통해 기대하는 이러한 긍정 적인 효과는 적어도 두 가지 근본적인 조건을 충족해야 한다.
첫 번째 조건은 ‘연구자나 관련 전문가뿐만 아니라 일반 시민 들이나 기업이 공공 데이터를 실제 이용한다 혹은 할 수 있다’ 라는 것이다. 두 번째 조건은 ‘그 공공 데이터가 이용자에게 유용하다’ 이다. 이 두 가지 조건을 충족하지 않는다면 공공데이 터의 효과는 측정할 수 없거나 제한적으로 평가할 수 밖에 없다. 따라서 공공데이터를 누가 왜 사용하는가? 혹은 사용하지 않는가? 도대체 얼마나 사용하는가? 라는 질문은 공공데이터 이용의 확산을 위한 핵심적인 경험적 연구의 질문이고 이 질문은 경영정보학에서 오랫동안 연구해온 기술 수용 분야의 핵심적인 질문과 이어져 있다.
정보통신부가 주관하고 한국지능정보사회진흥원과 통계청에서 매년 전국적으로 실시하는 ‘전자정부 서비스 이용실태조사’에 따르면 2015년부터 2018년까지 4년 동안 매년 4,000명의 설문조사 응답자 중 평균 3.6%(약 145명) 만이 중앙정부의 공공데이터 플랫폼(data.gov.kr)을 이용하고 있는 것으로 나타났다. 평균 3.6%는 아주 작은 숫자처럼 보이나 과대 해석해서 공공데이터가 거의 사용되지 않는다라고 섣불리 결론을 내릴 수는 없다. 왜냐하면 일반 시민들은 공공데이터 플랫폼을 이용해서 직접적으로 이를 이용할 수도 있지만 공공데이터를 활용하여 정부나 민간에서 제공하는 다양한 웹사이트나 모바일 앱을 통해 그 서비스를 사용한다면 공공데이터를 간접적으로 이용한다고 할 수 있기 때문이다. 그럼에도 불구하고 최근 4년간의 설문조사 결과들이 보여주는 공공데이터 플랫폼 이용율은 정부가 그동안 많은 예산과 노력을 통해 구축하고 제공하고 있는 공공데이터 이용이 많이 부족하다는 것이다.
공공데이터는 그러면 왜 이렇게 이용률이 높지 않을까? 데이터 과학자, 연구자, 정보통신 관련 종사자들은 인공지능을 위한 기계학습이 가능한 공공데이터가 부족하다는 지적도 한다. 그렇다면 일반 시민들의 공공데이터 이용에 영향을 미치는 요인은 무엇일까?
Souza와 그의 동료들은 최근 연구에서 브라질 시민들을 설문 조사한 데이터를 분석하여 시민들의 공공데이터 사용 의도에 영향을 미치는 촉진제와 장애요인이 무엇인지 논의하고 있다 (Souza et al., 2022). 이 설문조사에서 시민들에게 실제 사용 여부를 물어보지는 않았지만 사용 의도와 실제 사용 사이에 직접적이고 큰 영향 관계가 있다는 것을 고려하면 이 사용 의도에 영향을 미치는 요인들이 시사하는 바가 크다고 할 수 있다. 우선 사용 의도에 직접적으로 영향을 미치는 요인으로 정부가 좀더 개방적이고 접근 가능하다라고 하는 긍정적 인식이다. 그리고 전자정부의 접근 가능성에 대한 인지적 평가이다. 즉, ‘전자정부가 시민들에게 계속해서 정보를 제공하고 있다’, ‘세금낭비가 아니다’, ‘새로운 정보를 준다’ 같은 긍정적인 전자정부에 대한 태도가 직접적이고 긍정적으로 시민들이 공공데이터를 사용하고자 하는 의도에 영향을 미친다고 한다.
어쩌면 더 중요한 것은 이러한 개방형 정부와 전자정부에 대한 긍정적인 태도에 무엇이 영향을 미치는가 하는 것이다. 그들의 경험적 연구에서 발견한 세 가지 중요한 요인은 공공데이터 플랫폼의 이용 편리성(ease of use), 유용성(perceived usefulness), 그리고 전자정부에 대한 신뢰이다. 이용 편리성, 유용성, 전자정부신뢰에 대해 긍정적으로 평가하는 시민들은 정부가 개방적이고 접근 가능하다라고 긍정적으로 평가하고그 평가는 공공데이터를 이용하려는 의도에 긍정적이고 통계 적으로 유의미한 영향을 미친다. 즉 이용 편리성, 유용성, 정부신뢰는 공공데이터 이용에 간접적이지만 유의미한 영향을 준다고 할 수 있다.
이 중 공공데이터의 유용성과 관련해서 최근 다른 연구에서는(Ansari et al., 2022) 광범위한 공공데이터의 시각화를 연구한 논문들을 종합적으로 검토하여 어떻게 하면 공공데이터의 사용성(usability)과 유용성을 향상시킬 수 있을지 논의하고 있다. 이들 연구자들은 특히 유용성 향상에 데이터 시각화와 분석 도구(예: 대시보드)의 역할이 중요하다고 강조하고 있다. 그들이 살펴본 기존 연구 중에 예를 들어 공공데이터 이용자에게 텍스트 중심의 정보는 정보 과부화를 야기하여 그들이 인지하는 공공데이터 플랫폼의 유용성은 낮아지고 데이 터를 시각화 하는 것이 이용자의 정보 과부하를 줄여 공공데이터 플랫폼의 유용성이 높다고 인지한다(Lee et al., 2020) 는 결과는 시사하는 바가 크다. 그리고 이 연구에서는 공공데이터의 낮은 질(예: 데이터 포맷의 다양성, 문서화 되지 않은 데이터 사전화 혹은 메타 데이터, 데이터의 불완전성)이 공공데이터를 시각화 하는데 장애가 되는 공통된 제약요인으로 지적하고 있다.
인구통계학적 요인과 관련해서 또 다른 최근 연구에서는 (Begany et al., 2021) 공공데이터가 확산되던 초기인 2015년부터 11월부터 2016년까지 11월까지 1년간 누가 얼마나 뉴욕시의 건강 데이터를 사용하는지 구글 어넬리틱스(Google Analytics)를 이용해 분석하였다. 결과는 연구자들의 가설대로 나이가 젊은 사람일수록 건강 데이터 플랫폼에 머무는 시간이 길고 좀더 많은 데이터를 보는 것으로 나타났다. 하지만 그들의 가설과는 달리 남자가 여자보다 이 공공데이터 플랫 폼에 더 오래 머무르고 많은 데이터를 보는 것으로 나타났다.
또한 모바일이나 태블릿 컴퓨터 사용자 보다는 데스크탑 컴퓨터 사용자들이 이 건강 데이터 플랫폼에 더 적극적으로 이용하는 것으로 나타났다. 한편 앞에서 논의한 Souza 와 그의 동료들의 연구에 따르면(Souza et al., 2022) 유의미한 요인은 학력이다. 즉 대학교 학위 이상을 가진 고학력층과 고등학교 졸업 또는 그 이하의 학력을 가진 저학력층 사이에는 개방형 정부에 대한 태도와 공공데이터 사용 의도와의 관계에서 중요한 차이가 있다고 한다. 즉, 저학력층의 시민들은 고학력층 시민들보다 정부가 좀더 개방적이고 접근 가능하다고 평가했을 때 공공데이터를 사용할 의도가 높아진다는 관계가 통계적으로 약하다는 것이다.
이상에서 논의한 최근 연구 결과는 공공데이터를 제공하는 지방자치단체의 관리자와 리더들에게 누가 공공데이터 플랫폼을 사용하고 어떻게 시민들의 공공데이터 사용을 촉진할 것인가에 대한 함의를 주고 있다. 우선, 시민들이 공공데이터 플랫폼과 공공데이터를 쉽게 이용할 수 있도록 해야 한다. 즉, 공공데이터 플랫폼은 이를 사용하는 시민들이 공공데이터를 명확히 이해할 수 있게 디자인되어 있어야 한다. 그리고 공공데이터는 이용자가 다루기 쉬워야 한다. 이런 측면에서 특히 저학력층 같은 디지털 취약계층이 공공데이터에 쉽게 접근하고 이용할 수 있게 기존 디지털 취약계층을 위한 정보격차 교육과정에 공공데이터 이용을 포함하거나 강화해야 한다. 데이터의 포맷도 다양한 형태로 제공하고 메타 데이터도 제공해서 그 데이터의 정보를 제공해야 한다. 그리고 공공데이터는 그 플랫폼에서 찾기 쉬워야 한다. 공공데이터의 유용성을 높이기 위해서는 공공데이터의 소스를 제공하여 이용자들이 그 데이터에 대한 정당성과 신뢰감을 주어야 한다.
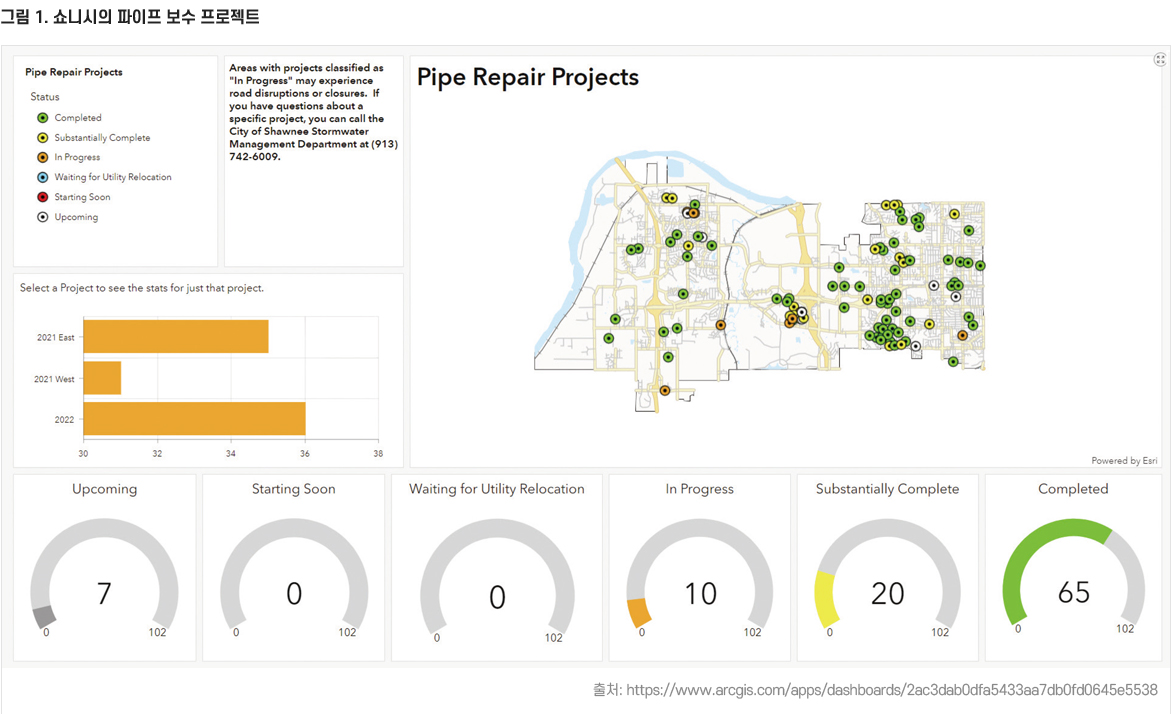
공공데이터가 가지고 있는 정보의 양과 질을 모두 향상시켜야 한다. 하지만 많은 양과 좋은 질의 공공데이터를 제공하는 것은 쉽지 않다. 더군다나 얼마나 많은 게 많은 양이고 얼마나 좋은 게 좋은 질이냐는 객관적으로 평가하기 더 쉽지 않다. 중요한 것은 이 두 가지가 어떻게 표현되었을 때 이용자들이 그 공공데이터의 유용성을 인지하는가 하는 것이다. 많은 양의 데이터가 텍스트 위주로 제공되었을 때 그 데이터의 질이 아무리 좋아도 이용자에게 정보 과부화가 발생할 수 있기 때문에 데이터의 시각화는 이용자의 유용성을 높이는 좋은 수단이 될 수 있다. 많은 미국의 지방자치단체는 GIS데이터와 정부 데이터를 통합하여 주민들의 매일 매일의 생활에 직접적으로 영향을 미칠 수 있는 정부 서비스를 시각화하여 제공하고 있다. 예를 들어 아래 그림 1은 미국 켄사스주 쇼니시(City of Shawnee) 정부에서 제공하는 공공데이터 시각화의 한 부분이다. 쇼니 시는 2021년 미국의 Government Technology 매거진에서 선정하는 인구 7만 5천명 이하의 중소 도시 중에 1등으로 선정된 디지털 혁신 시정부이다. 특히 이 데이터 시각화에서 보여주고 있는 것은 빗물이 흐를 수 있도록 만든 파이프의 보수 상태이다. 특징은 우선 파이프의 보수 상태를 측정한 데이터와 그 위치를 나타내는 GIS 데이터를 결합해서 쇼니시 지도위에 시각화해서 이용자에게 보여 주고 있다. 또한 지도 아래를 보면 파이프 보수 상태를 6개 단계로 나누어 파이프 보수가 어느정도 진전을 보이고 있는지 보여 주고 있다. 즉, 한 화면에 다양한 데이터를 보여주면서 지리정보와 시각화를 적절히 사용하여 공공데이터 이용자의 이 공공데이터의 유용성을 높여주고 있다. 뿐만 아니라 공공데이터의 시각화를 통해 시정부는 자신의 노력과 성과를 투명하게 보여주어 시민들에 대한 정부의 책임성을 높여주는 역할을 하기도 한다.
Ansari과 그 동료들은(Ansari et al., 2022) 질 높은 공공데이터를 만들고 시각화하기 위해서는 여러 학문 배경을 가진 인력으로 구성된 콘텐트 제작팀이 공공데이터를 시각화하고 향상시킬 필요가 있다고 제안한다. 그들은 기존의 조직 구조가 그러한 팀을 만드는데 제약이 된다고 지적하고 이를 극복하기 위해서는 지역사회의 다양한 조직을 공공데이터를 시각화하기 위한 디자인 과정에 참여시키고 대학의 연구 센터와 협업하여 그들이 지방자치단체의 공공데이터를 풍부하게 하고 시각화 하는데 ‘지식 브로커’ 역할을 하게 해야 한다고 주장한다. 그리고 그들은 적합한 시각화 기법을 선택해야 한다고 조언한다. 가장 적합한 기법은 이용자의 공공데이터를 통해 성취하려고 하는 것이 구체적으로 어떤 일인지에 달려있다. 예를 들어, 3차원으로 표현되는 시각화는 꼭 본래적으로 3차원 구조를 가진 모양의 것을 제외하고는 가능하면 피해야 한다. 그리고 앞에서 논의한 쇼니시의 파이프 보수 현황 시각화처럼 이용자들이 비교할 수 있도록 한 화면에 다양한 시각화 결과를 보여주는 게 바람직하다고 제안한다. 마지막으로 구글 어넬리틱스 같은 웹사이트 분석 도구처럼 쉽게 접근 가능한 도구를 이용해서 이용자 프로파일을 분석하는 것도 공공데이터 이용자가 누구인가를 이해하는 효과적인 방법이다(Begany et al., 2021).
Begany, G. M., Martin, E. G., & Yuan, X. (Jenny). (2021). Open government data portals: Predictors of site engagement among ear-ly users of Health Data NY. Government Information Quarterly, 38(4), 101614. https://doi.org/10.1016/j.giq.2021.101614
Jeon, C., Cho, D., & Chu, H.-Y. (2022). How Much Will You Pay to Use Open Data?: Evidence from the Seoul Metropolitan Government. Public Performance & Management Review, 45(2), 308–328. https://doi.org/10.1080/15309576.2021.1989313
Lee, T. (David), Lee-Geiller, S., & Lee, B.-K. (2020). Are pictures worth a thousand words? The effect of information presentation type on citizen perceptions of government websites. Government Information Quarterly, 37(3), 101482. https://doi.org/10.1016/j. giq.2020.101482
Souza, A. A. C. de, d’Angelo, M. J., & Lima Filho, R. N. (2022). Effects of Predictors of Citizens’ Attitudes and Intention to Use Open Government Data and Government 2.0. Government In-formation Quarterly, 39(2), 101663. https://doi.org/10.1016/j. giq.2021.101663



